If you’ve ever wondered if you can monitor hotspare disk activities from naviseccli, the answer is yes…. !
As expected you receive your automated email alerts when a system fault occurs, in this case a disk failure (and hopefully a dial-home event was triggered via ESRS)about a disk failure;

Using Naviseccli, you can get a more summarized view of what’s going on without navigating through the Unisphere interface;
|
1 |
naviseccli -h array-spa faults -list |
(obvisouly this will return all active faults)
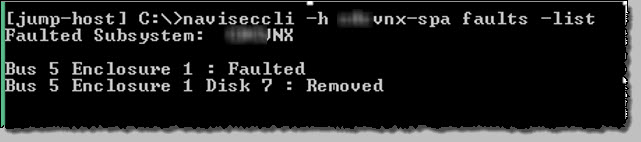
Let’s check for detailed disk info on disk 7 on Bu5 in enclosure 1;
|
1 |
naviseccli -h array-spa getdisk 5_1_7 |
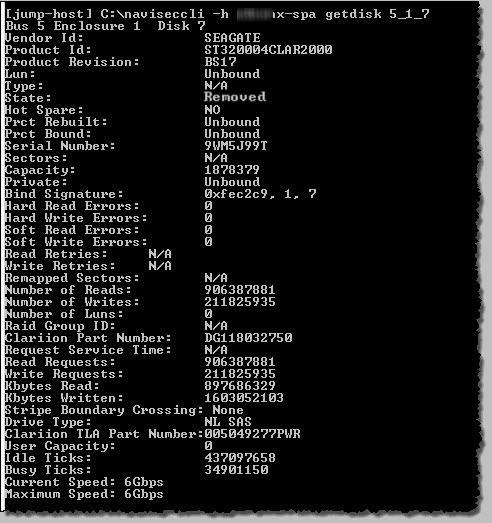
Check that a hot spare is replacing the failed disk; (I output all disk info to a file and then use findstr to search for the pattern, or grep if you’re accessing from a control workstation or linux host)
|
1 |
naviseccli arrayspa getdisk > h:\getdisks.txt |
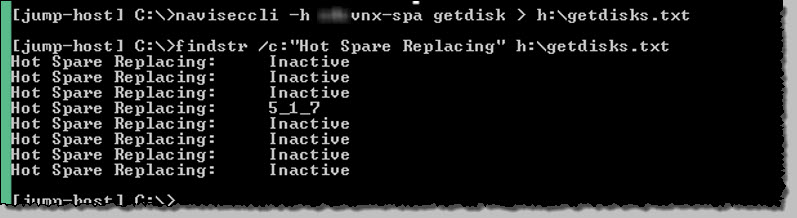
So we can see hot-sparing is active and replacing for the failed disk 5_1_7
(Before replacing the disk, wait until the hot-spare op completes, which can take considerable time with a NL-SAS disk in a large pool)
The failed disk was then replaced using USM. As can be seen, it’s now a Hitachi, as all the replacements seem to be now.
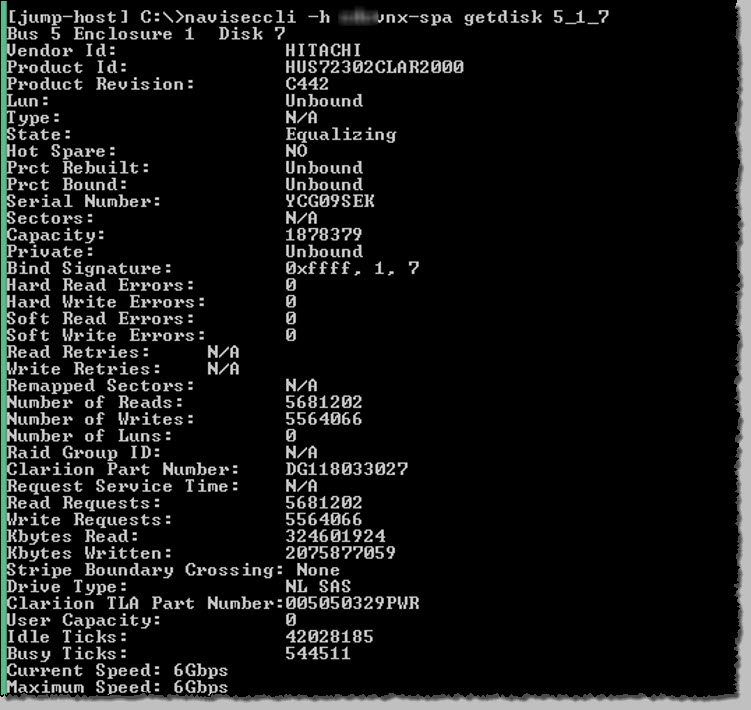
After the disk is replaced, the state should then change from Failed to ‘Equalizing’ as shown above indicating the automated copyback process has initiated.
I used to use the -rb switch to get the copyback progress but this only returns ‘unbound’ possible beucase this disk is part of a Storage Pool. This could probably be obtained using diskmon, but I didn’t have this handy at the time. This behaviour was evident also when running directly from the Control Workstation shell.

The familiar “Transitioning” badge in Unisphere;
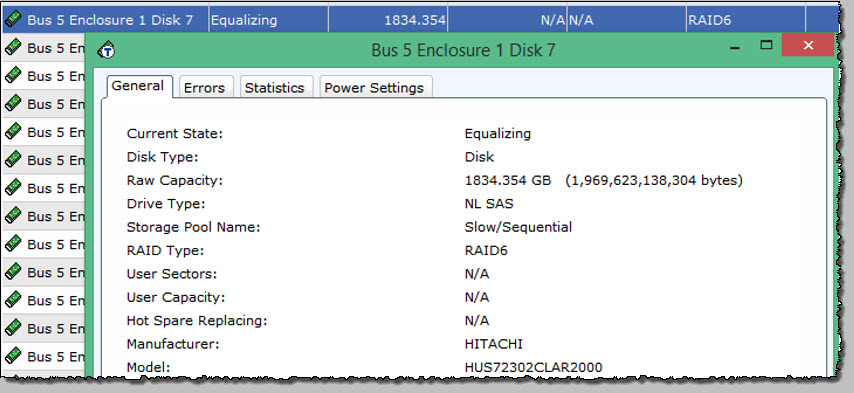
Once complete, the state will revert back to ‘Enabled’ and the exercise is over !

From Unisphere;

Cool !
Note that for VNX2 this process will be largely different due to the changed hotspare and drive mobility functionality. I’ll cover that process in the future.